Task execution process¶
What happens when a task is started¶
From the side of Lampyre¶
When you launch your task, using List of requests or macro, the following happens:
Lampyre creates an instance of your task class, then calls the execute() method, carrying there all parameters, instances of a ResultWriter and LogWriter and the path to temporary directory.
After this method exits, Lampyre harvests results, creates a table (and, optionally, some other visualization types) and considers the request to be complete.
From the side of a task¶
From the side of a task, a request execution is taking parameters from enter_params, doing some work and passing the result data to the result_writer.
And that’s it. execute() does not place objects and links to graph nor does it place anything on GIS map. All it does is it fills table(s) with data, and Lampyre does the rest. If you wonder how graphs and GIS are created/enriched with the help of the entity context menu, see Macros.
Writing results¶
ResultWriter class¶
ResultWriter’s responsibility is to pass data you give it back to Lampyre.
write_line() with header fields as keys and values for them.write_line() will attempt to detect the header on each call, which will affect the performance.Warning
The dictionary you pass to write_line() must include all header fields. To create such dictionary, you can use create_empty() method of your header class.
In the next example, a very popular python library - requests, is used to perform HTTP request to a given url and then write some of the obtained results to the table in your custom task. You can install this library with following command:
pip install requests
First, import all required classes:
from datetime import datetime
from lighthouse import Task, Header, Field, ValueType, EnterParamCollection, EnterParamField
from requests import Session
After that, we describe our Header to store requested url, date, response code and some of the HTTP response header values:
class ResponsesHeader(metaclass=Header):
display_name = 'Responses'
RequestUrl = Field('URL', ValueType.String)
Date = Field('Date', ValueType.Datetime)
StatusCode = Field('Status code', ValueType.Integer)
ReasonPhrase = Field('Reason phrase', ValueType.String)
CodeOk = Field('Request success', ValueType.Boolean)
ContentType = Field('Content-Type', ValueType.String)
ContentLength = Field('Content-Length', ValueType.Integer)
Server = Field('Server', ValueType.String)
Let’s describe our task. We add one enter parameter - URLs - so we can pass URLs to our request. This parameter will be marked as array and it will be required to run the task.
Our task will only use one table, so in get_headers() we can return only one header class. If a task has more than one table, HeaderCollection should be returned.
class ExampleTask(Task):
def get_id(self):
return '6496a2cf-8efa-493c-a68d-b95c5a212c38'
def get_display_name(self):
return 'ResultWriter example'
def get_category(self):
return 'Tutorial tasks'
def get_description(self):
return 'This tutorial task explains how to write execution results'
def get_headers(self):
# this is how to set additional header properties to customize it's fields
ResponsesHeader.set_property(ResponsesHeader.Date.system_name, 'datetime_format', 'yyyy/MM/dd HH:mm:ss')
return ResponsesHeader
def get_enter_params(self):
return EnterParamCollection(
EnterParamField('urls', 'URLs', ValueType.String, required=True, is_array=True)
)
Finally, in the execute() method we perform a request to each url and use the result_writer to write results to the table.
def execute(self, enter_params, result_writer, log_writer, temp_directory):
session = Session()
for url in enter_params.urls: # 'urls' marked as array, so this parameter will always be a list of values
response = session.get(url) # perform HTTP GET request and receive server response
line = ResponsesHeader.create_empty() # create a row for table
line[ResponsesHeader.RequestUrl] = url
# if field has ValueType.Datetime type, you can pass python datetime object
line[ResponsesHeader.Date] = datetime.now()
line[ResponsesHeader.StatusCode] = response.status_code
line[ResponsesHeader.ReasonPhrase] = response.reason
line[ResponsesHeader.CodeOk] = response.ok
line[ResponsesHeader.ContentType] = response.headers.get('Content-Type')
line[ResponsesHeader.ContentLength] = response.headers.get('Content-Length')
line[ResponsesHeader.Server] = response.headers.get('Server')
# this is where data is put to the table
result_writer.write_line(line, header_class=ResponsesHeader)
Now this custom request is ready. You can upload it to Lampyre, input some URLs and run it.
Logging¶
You can use logging in your task for debugging or informational purposes. The LogWriter class can deliver your messages to Lampyre during the task execution time.
Where task log goes¶
During the execution, the real-time updated task log can be viewed in the Execution log window. You can right-click a request in the Requests tab to bring this window to your front.
LogWriter class¶
To send messages to a log, the log_writer argument of execute() can be used. There are two methods to write messages:
Let’s change some code in our task to get its feedback from task:
def execute(self, enter_params, result_writer, log_writer, temp_directory):
session = Session()
for url in enter_params.urls: # 'urls' marked as array, so this parameter will always be a list of values
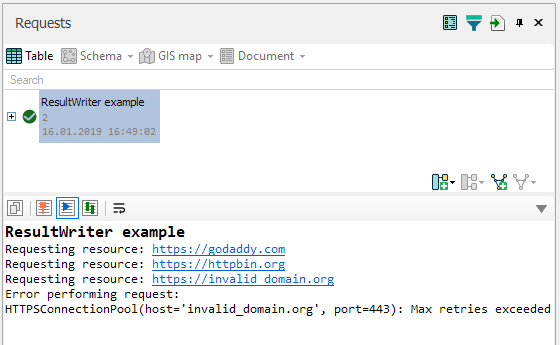
log_writer.info('Requesting resource: {}', url) # messages can be formatted using *args
try:
response = session.get(url) # perform HTTP GET request and receive server response
except Exception as e:
log_writer.info('Error performing request:')
log_writer.info(e)
continue
# ...rest of the code
This code will get something like this to the execution log window:
Debugging¶
During the development process, you may want to debug your code in IDE before uploading it to Lampyre. Here is a tip on how to to this:
create an entry point using a convenient
if __name__ == '__main__':instructioncreate substitutes for enter_params namedtuple,
ResultWriterandLogWriterinstances with corresponding properties and methodscreate an instance of your
Taskclass and call theexecute()method with these substitues
Lampyre won’t run the code in the __main__ section, so this code will not affect the task execution in Lampyre. This way you can even create tasks that also work just like regular python scripts.
Below is an example of a solution like this. And, of course, you can do it some other way.
if __name__ == '__main__':
import sys
class EnterParameters:
urls = ['https://lampyre.io']
class ResultWriterSub:
@staticmethod
def write_line(line: dict, header_class: Header):
print(','.join([str(v) for v in line.values()]))
class LogWriterSub:
@staticmethod
def info(message: str, *args):
print(message.format(args))
@staticmethod
def error(message: str, *args):
print(message.format(args), file=sys.stderr)
temp_dir = '.'
task = ExampleTask()
task.execute(EnterParameters, ResultWriterSub, LogWriterSub, temp_dir)